OCR
Deprecation Notice
This page describes features that have been removed or replaced in Luxonis Hub. Functionality may be limited and only available to Hub Original customers. Please refer to the up-to-date guides to provision devices, manage fleets, and deploy applications.
 The OCR process consists of two crucial stages: text detection and text recognition. The text detection model operates directly on the camera feed, swiftly identifying text regions within the image. Once detected, the text regions are then passed to the text recognition model, which runs on the host system. This model deciphers the text, converting it into machine-readable format.
The OCR process consists of two crucial stages: text detection and text recognition. The text detection model operates directly on the camera feed, swiftly identifying text regions within the image. Once detected, the text regions are then passed to the text recognition model, which runs on the host system. This model deciphers the text, converting it into machine-readable format.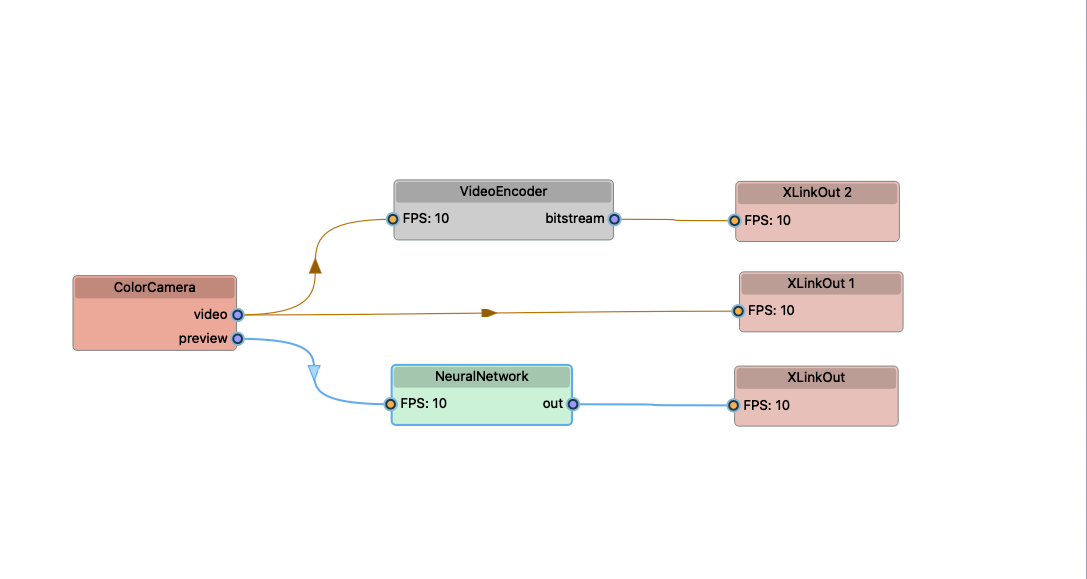 The application offers Open Library integration. It conducts searches based on the recognized text, retrieving information about the identified books.The application features a user-friendly frontend interface. Users can easily capture images of book covers or spines using their device's camera. The application then promptly processes these images, presenting the extracted text in a clear and organized manner on the frontend.
The application offers Open Library integration. It conducts searches based on the recognized text, retrieving information about the identified books.The application features a user-friendly frontend interface. Users can easily capture images of book covers or spines using their device's camera. The application then promptly processes these images, presenting the extracted text in a clear and organized manner on the frontend.View source code
