Use the following links to jump over the step by step intro and dive straight into Luxonis SDK and the full OAK software stack: DepthAI API, tools and examples across OAK USB, PoE and OAK4 cameras.
DepthAI API (Python/C++)
DepthAI v3 SDK library for building pipelines and apps on OAK and OAK4 cameras.
After you have you camera connected, the quickest way to start is by running OAK Viewer.
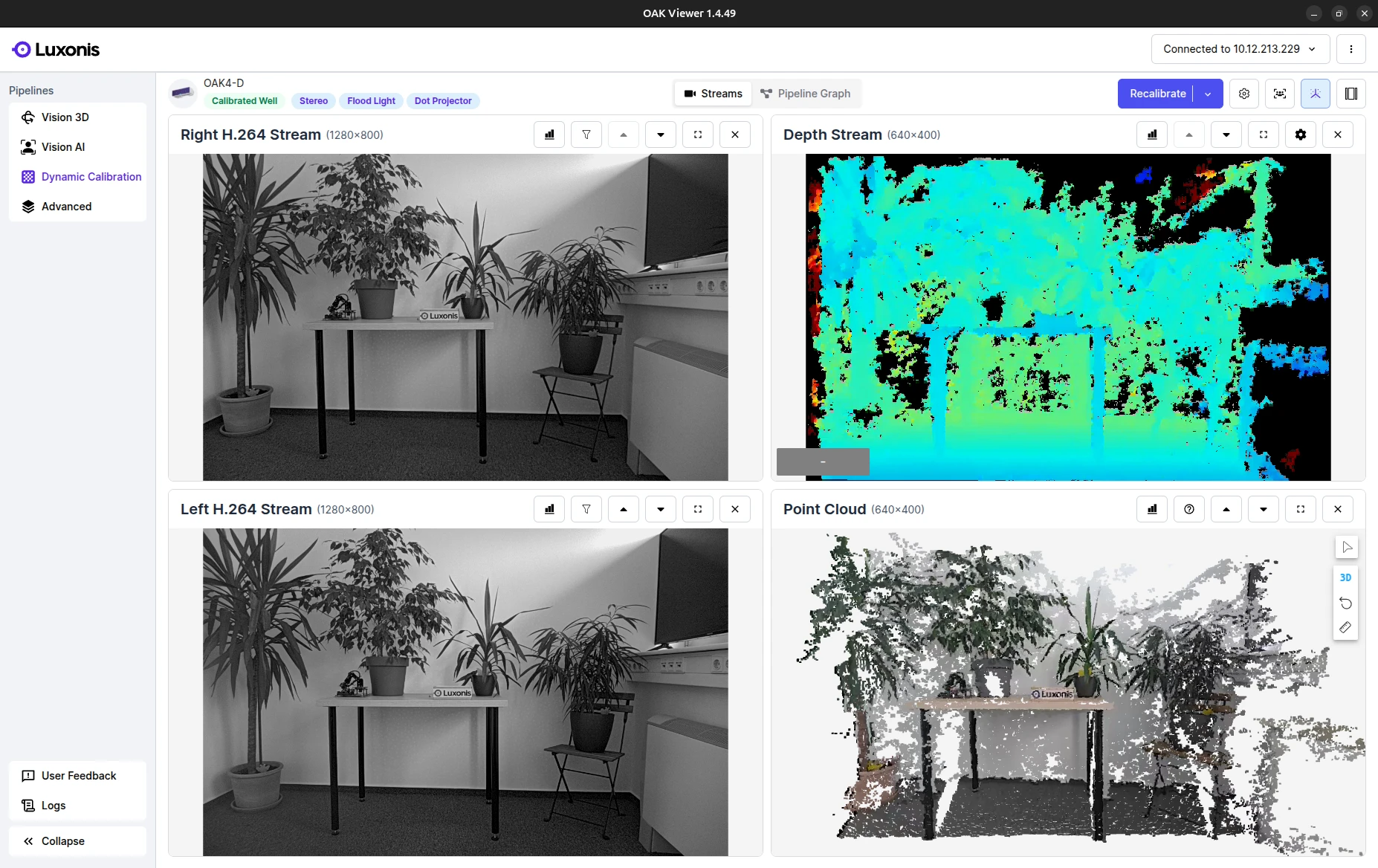
OAK Viewer
OAK Viewer is a desktop GUI application that allows you to visualize the camera's streams and interact with the device. It is available for Windows, macOS and Linux.
1# Connect to the device2oakctl connect
3# Clone the repo4git clone --depth 1 --branch main https://github.com/luxonis/oak-examples.git
5# Change directory to the generic-example6cd oak-examples/neural-networks/generic-example/
7# Run the app and follow instructions to open the web viewer8oakctl app run .
You just ran the App in Standalone mode.
See below for the difference between Standalone and Peripheral mode.
1# Clone the repo2git clone --depth 1 --branch main https://github.com/luxonis/oak-examples.git
3# Change directory to the generic-example4cd oak-examples/neural-networks/generic-example/
5# Create and enter virtual python environment6python3 -m venv venv
7source venv/bin/activate
8# Install requirements into the environment9pip install -r requirements.txt
10# Run the app and follow instructions to open the web viewer11python3 main.py
Windows
Command Line
1# Clone the repo2git clone --depth 1 --branch main https://github.com/luxonis/oak-examples.git
3# Change directory to the generic-example4cd oak-examples\neural-networks\generic-example\5# Install requirements6pip install -r requirements.txt
7# Run the app and follow instructions to open the web viewer8python main.py
You just ran the App in Peripheral mode.
See below for the difference between Standalone and Peripheral mode.
Standalone: The App is run only on the camera. Apps are deployed via oakctl.
Peripheral: The App runs on the camera, but the host computer remains connected to it over a TCP socket. Apps are run using the DepthAI API. Best used for quick prototyping and development.
Quickest way to get started with developing on your own is to use the template app. This app is a starting point for your own applications and includes all the necessary components to get you up and running.
Command Line
1# Install core packages2pip install depthai --force-reinstall
3# Clone the template app4git clone https://github.com/luxonis/oak-template.git
5# Change directory to the template app6cd oak-template
7# Install requirements8pip install -r requirements.txt
This will download the template / cookie-cutter app to your current directory.