Performance Optimization
Performance Optimization
Understanding Performance Metrics
- Latency: refers to the delay or lag between the input (such as an image or video frame) and the corresponding output or response from a neural network.
- Throughput: refers to the amount of data or the number of tasks a computer vision system can process within a given period.
- Accuracy: measures how well a system or model performs in terms of correctness.
Hardware Considerations
RVC2 NN Performance
| Model name | Size | FPS | Latency [ms] |
|---|---|---|---|
| MobileOne S0 | 224x224 | 165.5 | 11.1 |
| Resnet18 | 224x224 | 94.8 | 19.7 |
| DeepLab V3 | 256x256 | 36.5 | 48.1 |
| DeepLab V3 | 513x513 | 6.3 | 253.1 |
| YoloV6n R2 | 416x416 | 65.5 | 29.3 |
| YoloV6n R2 | 640x640 | 29.3 | 66.4 |
| YoloV6t R2 | 416x416 | 35.8 | 54.1 |
| YoloV6t R2 | 640x640 | 14.2 | 133.6 |
| YoloV6m R2 | 416x416 | 8.6 | 190.2 |
| YoloV7t | 416x416 | 46.7 | 37.6 |
| YoloV7t | 640x640 | 17.8 | 97.0 |
| YoloV8n | 416x416 | 31.3 | 56.9 |
| YoloV8n | 640x640 | 14.3 | 123.6 |
| YoloV8s | 416x416 | 15.2 | 111.9 |
| YoloV8m | 416x416 | 6.0 | 273.8 |
To see the performance of more RVC2 NN models, please refer to this spreadsheet.
Model Optimization Techniques
Luxonis-Specific Optimizations
Number of SHAVES
Lowering camera FPS to match NN FPS
NN input queue size and blocking behavior
setQueueSize() method) is reached, any additional messages from the device will be blocked. The library will wait until it can add new messages to the queue. When the queues are non-blocking, in the previous scenario, the library will discard the oldest message, add the new one to the queue, and then continue its processing loop. If your network has a higher latency and cannot process that many frames, it might improve the performance by setting the input queue of your neural network to non-blocking.Quantization (only applicable for RVC3 conversion)
coco128.zip (download from here). However, we suggest using images from your training or validation set for the best quantization and lowest accuracy drop.To install POT, use the following commands inside your Python environment:Command Line
1python -m pip install --upgrade pip
2pip install openvino-dev==2022.1pot-config.json file:JSON
1{
2 "model": {
3 "model_name": "yolov6n",
4 "model": "path/to/model.xml",
5 "weights": "path/to/model.bin"
6 },
7 "engine": {
8 "device": "CPU",
9 "type": "simplified",
10 "data_source" : "/path/to/coco128/images/train2017/"
11 },
12 "compression": {
13 "target_device" : "VPU",
14 "algorithms": [
15 {
16 "name": "DefaultQuantization",
17 "params": {
18 "stat_subset_size": 300
19 },
20 }
21 ]
22 }
23}Command Line
1pot -c pot-config.json -dProfiling and Benchmarking
log level (or lower), depthai will print the usage of hardware resources, specifically CPU/RAM consumption, temperature, CMX slices, and SHAVE core allocation.You can set the debugging level like this:Command Line
1DEPTHAI_LEVEL=info python3 script.pyDepthAI Pipeline Graph
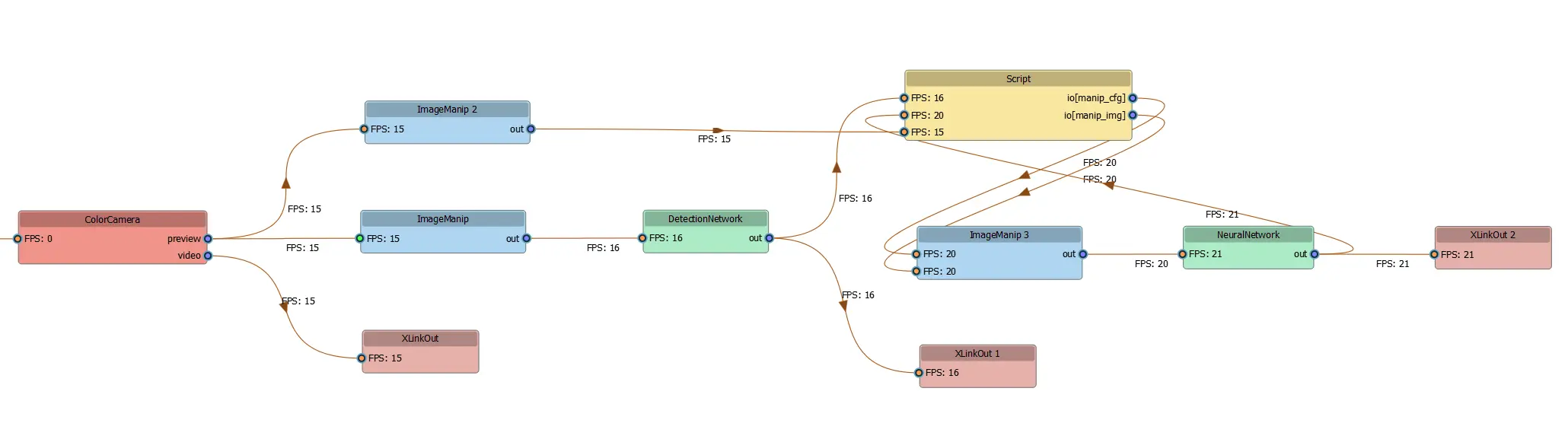
Command Line
1pip install git+https://github.com/luxonis/depthai_pipeline_graph.gitmain.py script, use this command:Command Line
1pipeline_graph "python main.py -cam"Troubleshooting Common Performance Issues
trace, depthai will log operation times for each node/process.To visualize the network, you can use netron.app. You can investigate which operation could cause a bottleneck and then test your hypothesis by pruning the model before this operation. To prune a model, you should set the --output flag of the model optimizer (mo) to the given node. To read more about pruning, please see the documentation. After pruning the model, compile it, measure its latency, and compare it with the latency of the original (not pruned) model to see if your hypothesis was correct.