Spatial AI¶
Spatial AI allows robots or computers to perceive the world as a human can - what objects or features are - and where they are in the physical world. DepthAI platform leverages Spatial AI by fusing AI capabilities with depth perception on the OAK camera itself.
There are a few different approaches to achieve AI + depth fusion:
1. Neural inference fused with depth map¶
DepthAI can fuse neural inference (object/landmark detection) results with a depth map to estimate spatial coordinates (XYZ) of all objects/landmarks in the scene.
This technique is excellent for existing (pre-trained) 2D object/feature detectors as it runs inference on color/mono frames, and uses resulting bounding boxes to determine ROIs (regions-of-interest). DepthAI then averages depth from depth map inside these ROIs and calculates spatial coordinates from that (calculation here).
3D Object Localization¶
First, let us define what ‘Object Detection’ is. It is the technical term for finding the bounding box of an object of interest, in an image’s pixel space (i.e., pixel coordinates),.

3D Object Localization (or 3D Object Detection) is all about finding objects in physical space instead of pixel space. It is useful when measuring or interacting with the physical world in real-time.
Below is a visualization to showcase the difference between Object Detection and 3D Object Localization:

DepthAI extends these 2D neural networks (eg. MobileNet, Yolo) with spatial information to give them 3D context.
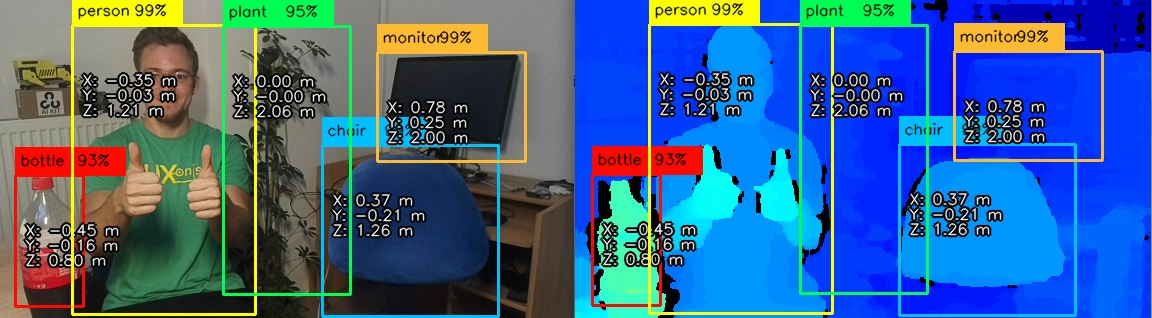
On the image above, a depthai application runs MobileNet object detector and fuses object detections with a depth map to provide spatial coordinates (XYZ) of objects it sees: person, potted plant, bottle, and chair.
3D Landmark Localization¶
An example would be a hand landmark detector on DepthAI. With a regular camera, this network returns the 2D (XY) coordinates of all 21 hand landmarks (contours of all joints in fingers). Using this same network with DepthAI, these 21 hand landmarks are now 3D points in physical space instead of 2D points in pixel space

Demos: hand landmark (above), human pose landmark, and facial landmark detection demos.
2. Semantic depth¶
One of the classic problems in autonomous robotic navigation/actuation are unknown objects. Known objects are specified before the installation to be encountered - such as tools, other machines, workers, equipment, and facilities.
We cannot anticipate unknown objects - including those unknowable or never-before-seen. Training an object detector is sufficient for known objects as this is a “positive” form of object detection: “Pile in the path, stop.” “Shovel in the path, stop.” etc.
Such generic obstacle avoidance scenarios require a “negative” object detection system, and a very effective technique is to use semantic segmentation of RGB, Depth, or RGB+Depth.

The image above was taken from Greenzie’s robotic lawnmowers (from OpenCV weekly livestream).
In such a “negative” system, the semantic segmentation system is trained on all the surfaces that are not objects. So anything that is not that surface is considered an object - allowing the navigation to know its location and take commensurate action (stop, go around, turn around, etc.). So the semantic depth is extremely valuable for object avoidance and navigation planning application.

On the image above, a person semantic segmentation model is running on RGB frames, and, based on the results, it crops depth maps only to include the person’s depth.
3. Stereo neural inference¶
In this mode, the neural inference (landmark detection) is run on the left and right cameras to produce stereo inference results. Unlike monocular neural inference fused with stereo depth - there is no max disparity search limit - so the minimum distance is purely limited by the greater of (a) horizontal field of view (HFOV) of the stereo cameras themselves and (b) the hyperfocal distance of the cameras (minimal distance for objects to be in focus).
After we have 2D positions of landmarks from both left/right cameras, we can calculate the disparity of the results, which are then triangulated with the calibrated camera intrinsics to give the 3D position of all the detected features.
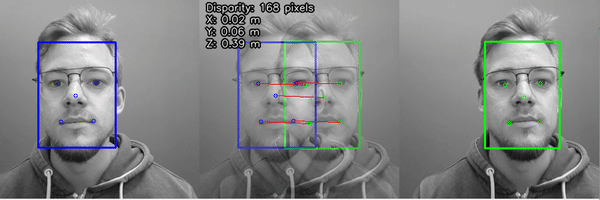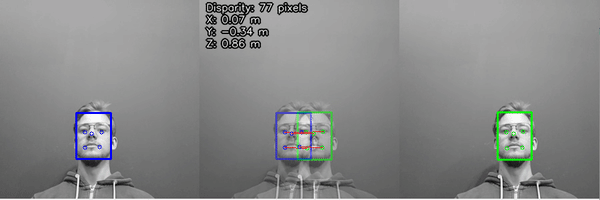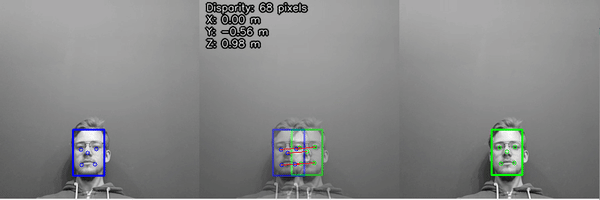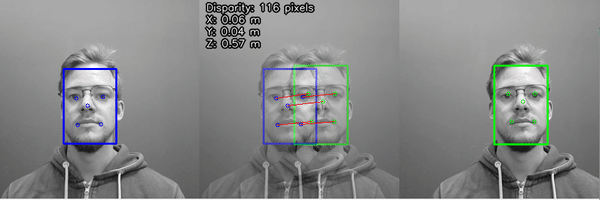
For more information, check out the Stereo neural inference demo.
Examples include finding the 3D locations of:
Facial landmarks (eyes, ears, nose, edges of the mouth, etc.)
Features on a product (screw holes, blemishes, etc.)
Joints on a person (e.g., elbow, knees, hips, etc.)
Features on a vehicle (e.g. mirrors, headlights, etc.)
Pests or disease on a plant (i.e. features that are too small for object detection + stereo depth)
This mode does not require the neural networks to be trained with depth data. DepthAI takes standard, off-the-shelf 2D networks (which are significantly more common) and uses this stereo inference to produce accurate 3D results.