性能优化
理解性能指标
- 延迟:指输入(如图像或视频帧)与神经网络的相应输出或响应之间的延迟或滞后。
- 吞吐量:指计算机视觉系统在给定时间内可以处理的数据量或任务数量。
- 准确性:衡量系统或模型在正确性方面的表现。
硬件注意事项
RVC2 NN 性能
| 模型名称 | 尺寸 | FPS | 延迟 [毫秒] |
|---|---|---|---|
| MobileOne S0 | 224x224 | 165.5 | 11.1 |
| Resnet18 | 224x224 | 94.8 | 19.7 |
| DeepLab V3 | 256x256 | 36.5 | 48.1 |
| DeepLab V3 | 513x513 | 6.3 | 253.1 |
| YoloV6n R2 | 416x416 | 65.5 | 29.3 |
| YoloV6n R2 | 640x640 | 29.3 | 66.4 |
| YoloV6t R2 | 416x416 | 35.8 | 54.1 |
| YoloV6t R2 | 640x640 | 14.2 | 133.6 |
| YoloV6m R2 | 416x416 | 8.6 | 190.2 |
| YoloV7t | 416x416 | 46.7 | 37.6 |
| YoloV7t | 640x640 | 17.8 | 97.0 |
| YoloV8n | 416x416 | 31.3 | 56.9 |
| YoloV8n | 640x640 | 14.3 | 123.6 |
| YoloV8s | 416x416 | 15.2 | 111.9 |
| YoloV8m | 416x416 | 6.0 | 273.8 |
要查看更多 RVC2 NN 模型的性能,请参阅此电子表格:this。
模型优化技术
Luxonis 特有优化
SHAVES 数量
降低摄像头 FPS 以匹配 NN FPS
NN 输入队列大小和阻塞行为
setQueueSize() 方法设置)达到时,来自设备的任何其他消息都将被阻塞。库将等待直到它可以将新消息添加到队列中。 当队列是非阻塞的时,在上述情况下,库将丢弃最旧的消息,将新消息添加到队列,然后继续其处理循环。 如果您的网络延迟较高且无法处理这么多帧,则将神经网络的输入队列设置为非阻塞可能会提高性能。量化(仅适用于 RVC3 转换)
coco128.zip(从此处下载)。但是,为了获得最佳量化效果和最低的准确度下降,我们建议使用来自训练或验证集的图像。要安装 POT,请在您的 Python 环境中使用以下命令:Command Line
1python -m pip install --upgrade pip
2pip install openvino-dev==2022.1pot-config.json 文件:JSON
1{
2 "model": {
3 "model_name": "yolov6n",
4 "model": "path/to/model.xml",
5 "weights": "path/to/model.bin"
6 },
7 "engine": {
8 "device": "CPU",
9 "type": "simplified",
10 "data_source" : "/path/to/coco128/images/train2017/"
11 },
12 "compression": {
13 "target_device" : "VPU",
14 "algorithms": [
15 {
16 "name": "DefaultQuantization",
17 "params": {
18 "stat_subset_size": 300
19 },
20 }
21 ]
22 }
23}Command Line
1pot -c pot-config.json -d性能分析和基准测��试
log 级别(或更低),depthai 将打印硬件资源的使用情况,特别是 CPU/RAM 消耗、温度、CMX 切片和 SHAVE 核心分配。您可以通过以下方式设置调试级别:Command Line
1DEPTHAI_LEVEL=info python3 script.pyDepthAI Pipeline Graph
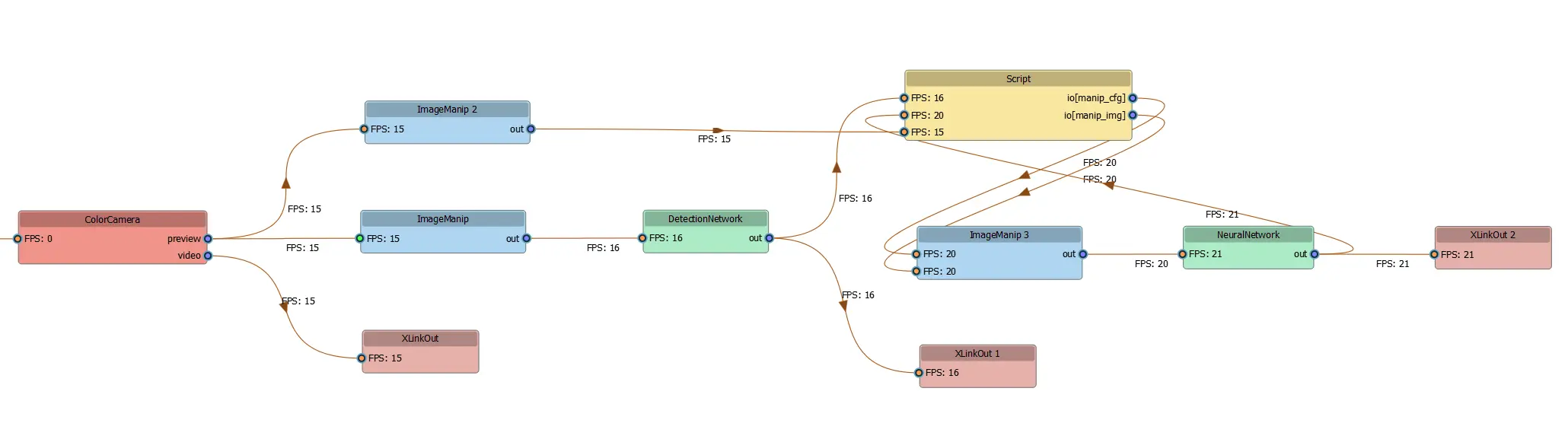
Command Line
1pip install git+https://github.com/luxonis/depthai_pipeline_graph.gitmain.py 脚本中定义的 DepthAI pipeline,请使用此命令:Command Line
1pipeline_graph "python main.py -cam"故障排除常见性能问题
trace,depthai 将记录每个节点/进程的操作时间。要可视化网络,您可以使用 netron.app。您可以调查哪个操作可能导致瓶颈,然后通过在此操作之前修剪模型来测试您的假设。要修剪模型,您应该将模型优化器 (mo) 的 --output 标志设置为给定的节点。要详细了解修剪,请参阅文档。修剪模型后,编译它,测�量其延迟,并将其与原始(未修剪)模型的延迟进行比较,以查看您的假设是否正确。